|
I am currently a researcher at the Embodied AI Center, Shanghai AI Laboratory. I received my Ph.D. in Computer Science and Technology from Shanghai Jiao Tong University, where I worked in the MVIG Lab under the supervision of Prof. Cewu Lu. I now collaborate closely with Jingbo Wang and Jiangmiao Pang, and previously gained valuable experience at the General Vision Lab, BIGAI. My research focuses on loco-manipulation, unifying whole-body humanoid locomotion with dexterous-hand manipulation. I am seeking highly motivated interns to join our team at Shanghai AI Lab—interested candidates are warmly encouraged to reach out via email. / Google Scholar / Github |

|
|
|
|
|
Qingwei Ben*, Botian Xu*, Kailin Li*, Feiyu Jia, Wentao Zhang, Jingping Wang, Jingbo Wang, Dahua Lin, Jiangmiao Pang (*=equal contribution) project page / arxiv Gallant is a voxel-grid–based perception-learning framework that uses LiDAR voxelization and a z-grouped 2D CNN to learn end-to-end humanoid locomotion policies in complex 3D constrained environments. By providing global 3D coverage beyond elevation maps and depth images, and training in a high-fidelity LiDAR simulator, a single Gallant policy robustly handles stairs, narrow passages, lateral clutter, overhead constraints, and multi-level structures with near-perfect success. |
|
|
Kailin Li, Puhao Li, Tengyu Liu, Yuyang Li, Siyuan Huang CVPR, 2025 project page / arxiv / Github / Overview(中文) / Talk(中文) Our objective is to develop a policy that enables dexterous robotic hands to replicate human hands accurately–object interaction trajectories in simulation while satisfying the tasks' semantic manipulation constraints. The key innovation of ManipTrans is to frame this transfer as a two-stage process: first, a pre-training trajectory imitation stage focusing solely on hand motion, and second, a specific action fine-tuning stage that addresses interaction constraints. By leveraging ManipTrans, we transfer multiple hand–object datasets to robotic hands, creating DexManipNet—a large-scale dataset featuring previously unexplored tasks such as pen capping and bottle unscrewing, that facilitate further policy training for dexterous hands and enabling real-world deployments. |

|
Kailin Li, Jingbo Wang, Lixin Yang, Cewu Lu, Bo Dai ECCV, 2024 (Oral Presentation) project page / arxiv / dataset Generating human grasps involves both object geometry and semantic cues. This paper introduces SemGrasp, a method that infuses semantic information into grasp generation, aligning with language instructions. Leveraging a unified semantic framework and a Multimodal Large Language Model (MLLM), SemGrasp is supported by CapGrasp, a dataset featuring detailed captions and diverse grasps. Experiments demonstrate SemGrasp's ability to produce grasps consistent with linguistic intentions, surpassing shape-only approaches. |
|
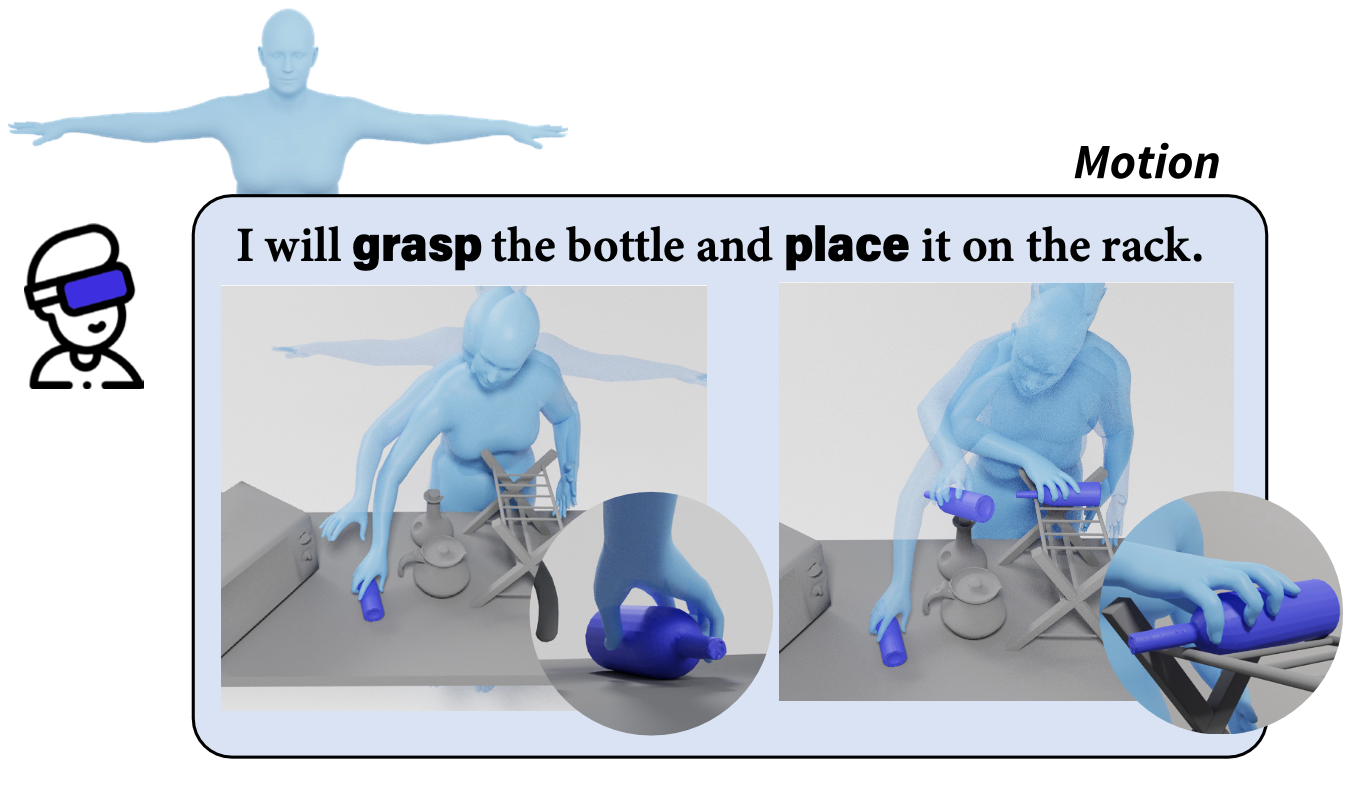
Kailin Li, Lixin Yang, Zenan Lin, Jian Xu, Xinyu Zhan, Yifei Zhao, Pengxiang Zhu, Wenxiong Kang, Kejian Wu, Cewu Lu AAAI, 2024 project page Rearranging objects is key in human-environment interaction, and creating natural sequences of such motions is crucial in AR/VR and CG. Our work presents Favor, a unique dataset that captures full-body virtual object rearrangement motions through motion capture and AR glasses. We also introduce a new pipeline, Favorite, for generating lifelike digital human rearrangement motions driven by commands. Our experiments show that Favor and Favorite produce high-fidelity motion sequences. |
|
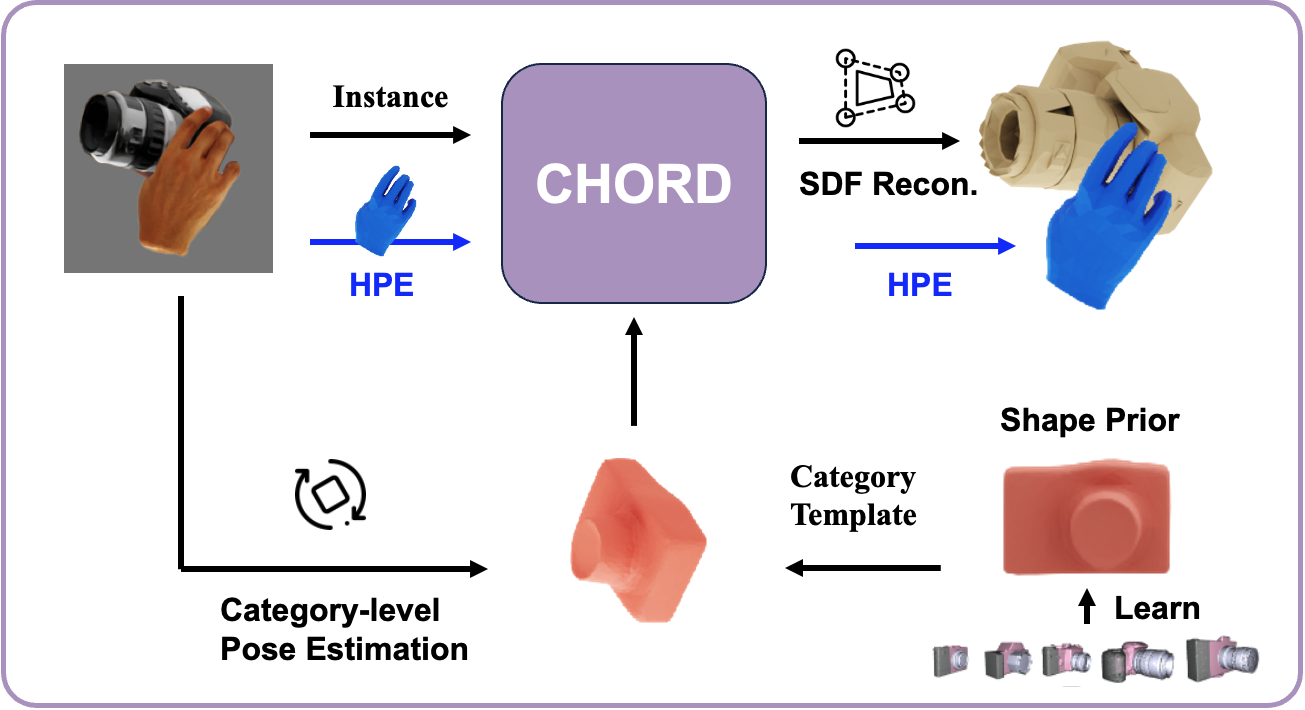
Kailin Li, Lixin Yang, Haoyu Zhen Zenan Lin, Xinyu Zhan, Licheng Zhong, Jian Xu, Kejian Wu, Cewu Lu ICCV, 2023 project page / arxiv / dataset / PyBlend We proposed a new method Chord which exploits the categorical shape prior for reconstructing the shape of intra-class objects. In addition, we constructed a new dataset, COMIC, of category-level hand-object interaction. Comic encompasses a diverse collection of object instances, materials, hand interactions, and viewing directions, as illustrated. |
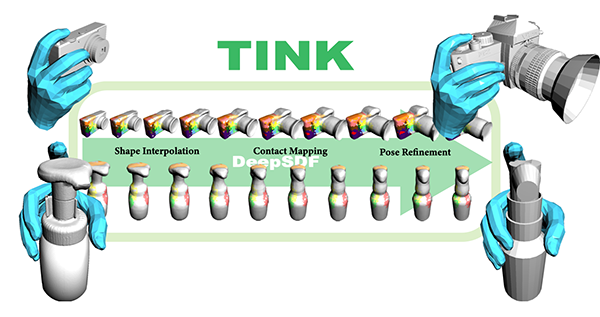
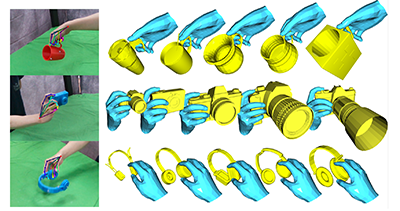
|
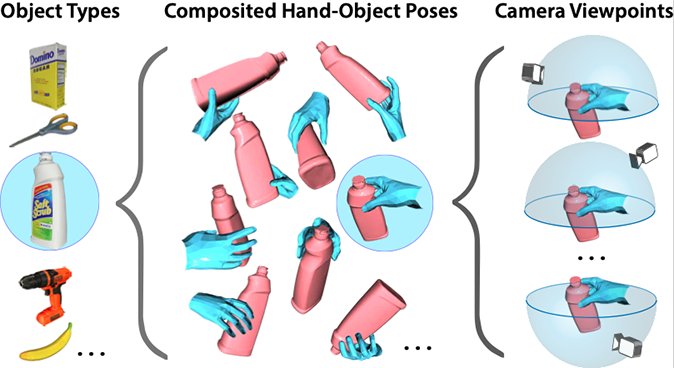
Lixin Yang*, Kailin Li*, Xinyu Zhan*, Fei Wu, Anran Xu, Liu Liu, Cewu Lu (*=equal contribution) CVPR, 2022 project / arxiv / code / dataset Learning how humans manipulate objects requires machines to acquire knowledge from two perspectives: one for understanding object affordances and the other for learning human interactions based on affordances. In this work, we propose a multi-modal and rich-annotated knowledge repository, OakInk, for the visual and cognitive understanding of hand-object interactions. Check our website for more details! |
|
Lixin Yang*, Kailin Li*, Xinyu Zhan, Jun Lv, Wenqiang Xu, Jiefeng Li, Cewu Lu (*=equal contribution) CVPR, 2022 (Oral Presentation) project / arxiv / code We propose a lightweight online data enrichment method that boosts articulated hand-object pose estimation from the data perspective. During training, ArtiBoost alternatively performs data exploration and synthesis. Even with a simple baseline, our method can boost it to outperform the previous SOTA on several hand-object benchmarks. |

|
Daiheng Gao*, Yuliang Xiu*, Kailin Li*, Lixin Yang*, Feng Wang, Peng Zhang, Bang Zhang, Cewu Lu, Ping Tan (*=equal contribution) NeurIPS, 2022 - Datasets and Benchmarks Track project (dataset) / paper / arxiv / code / video In this paper, we extend MANO with more Diverse Accessories and Rich Textures, namely DART. DART is comprised of 325 exquisite hand-crafted texture maps which vary in appearance and cover different kinds of blemishes, make-ups, and accessories. We also generate large-scale (800K), diverse, and high-fidelity hand images, paired with perfect-aligned 3D labels, called DARTset. |

|
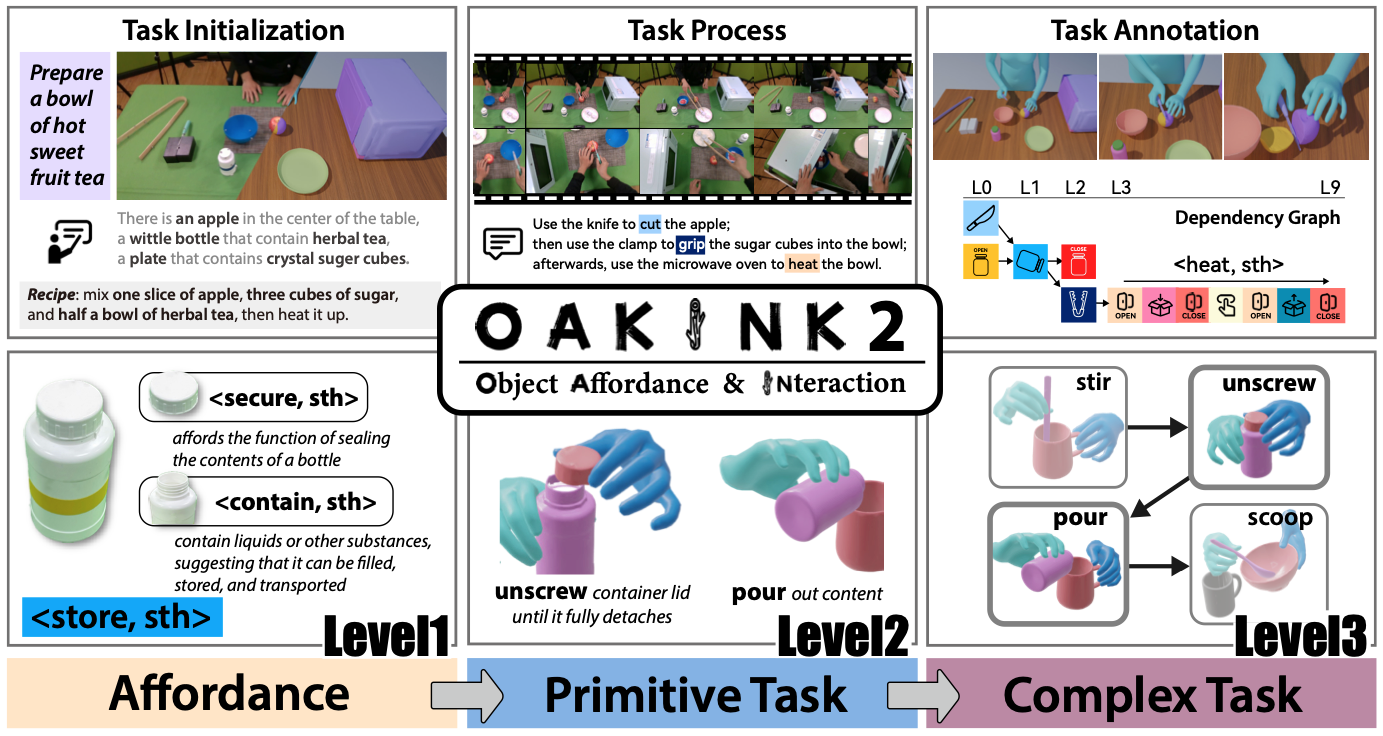
Xinyu Zhan*, Lixin Yang*, Yifei Zhao, Kangrui Mao, Hanlin Xu, Zenan Lin, Kailin Li, Cewu Lu CVPR, 2024 project page / arxiv OAKINK2 is a rich dataset focusing on bimanual object manipulation tasks involved in complex daily activities. It introduces a unique three-tiered abstraction structure—Affordance, Primitive Task, and Complex Task—to systematically organize task representations. By emphasizing an object-centric approach, the dataset captures multi-view imagery and precise annotations of human and object poses, aiding in applications like interaction reconstruction and motion synthesis. Furthermore, we propose a Complex Task Completion framework that utilizes Large Language Models to break down complex activities into Primitive Tasks and a Motion Fulfillment Model to generate corresponding bimanual motions. |

|
Licheng Zhong*, Lixin Yang*, Kailin Li, Haoyu Zhen Mei Han, Cewu Lu, 3DV, 2024 project page / arxiv / code / data Color-NeuS focuses on mesh reconstruction with color. We remove view-dependent color while using a relighting network to maintain volume rendering performance. Mesh is extracted from the SDF network, and vertex color is derived from the global color network. We conceived a in hand object scanning task and gathered several videos for it to evaluate Color-NeuS. |
|
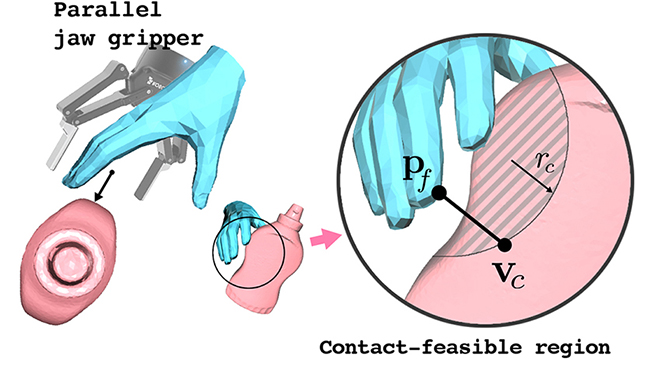
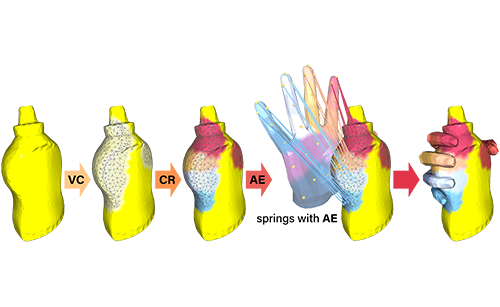
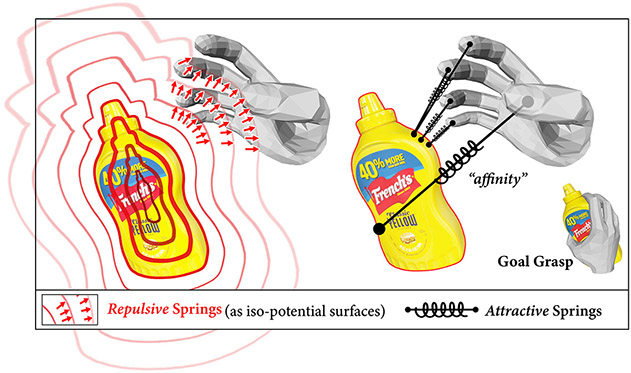
Lixin Yang, Xinyu Zhan, Kailin Li, Wenqiang Xu, Jiefeng Li, Cewu Lu ICCV, 2021 project / paper / supp / arxiv / code / 知乎 We highlight contact in the hand-object interaction modeling task by proposing an explicit representation named Contact Potential Field (CPF). In CPF, we treat each contacting hand-object vertex pair as a spring-mass system, Hence the whole system forms a potential field with minimal elastic energy at the grasp position. |
|
|
| International top-tier conference workshop HANDS Workshop @ ICCV 2025 Co-organizer: Lead, Embodied Manipulation Challenge. | Conference reviewer for ICLR25/26,ICML25,NeurIPS24/25,CVPR22/24/25,ICCV23,ECCV22/24, AAAI25, 3DV22. |